慣れもあって私はWord+TRADOSで翻訳作業をしていることが多い。
ただ進捗がページ数でわかりにくいのがちょっとした悩みだった。
そもそもが数枚ならば悩むまでもないが、TRADOSが威力を発揮するのはもっぱら長編。
いかんせん、画面上は原文と訳文が交互に並ぶ表示となるため
Wordでのページ数表示が3~5割増しになってしまい結局どこまでやったのか分からなくなる。
今回とある大規模案件で60枚が104枚まで膨れあがっていたのだが、
実はWordの「印刷プレビュー」機能ならばページ数が正確に表示されるということに気づいた。
作業中の文書を印刷したことがないので知らなかったが、
TRADOS処理した原文は「訳文を生成」しなくても印刷されないようだ。
したがって、印刷プレビューでは「訳文を生成」と同然の表示になる。
すなわち
「印刷プレビュー」画面において
総ページ数-訳文のみ表示されるページ数=残り原文ページ数
知っている人には馬鹿げた問題であろうが、私にはちょっとした発見だった。
PDF内の表をWordに取り込む方法
昨年末の案件で使った方法をメモ。
PDFが文字情報を(画像としてではなく)含んでいる場合、
Adobe Readerで「ファイル」→「テキストとして保存」するとテキストファイルにできる。
良くも悪くも単純なテキストとして書き出されるため、
・日本語版での中国語の書き出しは失敗する(多言語でもあるかも)
・表がべた打ち文字列になる
これを一挙に解決する対症療法を思いついた。
0. PDFファイルと貼り付け先のWord文書を開いておく
1. PDF上の使いたい文字列を全て選択
2. Wordで「編集」→「形式を選択して貼り付け」→「Unicodeテキスト」を選ぶ
3. 貼り付けた結果をよく見る(笑)
A・表の各行が段落記号で区切られている
B・表の各列が半角スペースなどで区切られている
#この2点が目視できない場合、「ツール」→「オプション」→「表示」タブで
「編集記号の表示」をいじる
4. Word上で表にしたい文字列を全て選択し、「罫線」→「変換」→「文字列を表にする」
5. 「区切り記号」に上記3Bの区切り記号を指定する
6. Wordの表できあがり
ところどころ区切り記号の過不足がある場合は「元に戻す」で3.の段階に戻り、
半角スペースの挿入なり削除なりの調整をして4.に進む。
……文で説明するとややこしそうだが、やってみると便利。
自分で書いた表に一部ずつ貼り付けるより数倍お手軽なはず。
訳抜け探し
全部で90枚か100枚かという大量の案件を受注。
一週間かかりきりでどうにかやっつけた。
が。目を通してみると訳抜けがちらほら出てきた。
どうしても抜けてしまうのは後で潰す必要がある。
目視で三週してもまだ見つかることに業を煮やしたり落胆したり。
そこで思いついたのはEXCELの活用だった。
原文を左、訳文を右の列に貼り付けて同一かどうかを式で判定。
フィルタをかけると……まだ6件あるorz
ともあれこれで何とかなったので、メモがてら書いておく。
エキサイト翻訳の頼もしさ
エキサイト翻訳は英語、中国語ともになかなかよい和訳をしてくれる。
長ったらしい文章をざっと見たいときなどに普段から重宝しているのだが、
新たな使い勝手の良さを発見してしまった。
表示される訳文が画面上で上書き修正できてしまうのである。
少々の手直しで使えそうな訳文が表示されたときなど、非常に便利だ。
更に邪道な用法としては、段落が長すぎてTRADOSのウインドウを表示しきれないとき
エキサイト翻訳のサイト上で対訳を作成してしまうというのがある。
大幅な修正というより自力で翻訳をするはめになっても余り損した気がしない。
原文と訳文が左右にきれいに並ぶだけでも意外と価値があるものだ。
区切り文字のない中英対照表を中国語と英語に分割
按半周进行的多周期控制 multicycle controlled by half-cycle
といった感じで前半に中国語、後半に英語の綴られたページを発見した。
1000組を超える大量の通信関係用語集である。
使えそうな用語集なので早速Multitermに取り込もうと思ったが、
Excelに貼り付けたテキストをよく見ると中国語と英語の間に区切り文字もタブもない。
文字列の先頭からいくつが全角文字かが分かれば簡単に仕分けできるのだが、
どうもそこまで便利な関数は転がっていないらしい。
そこで苦肉の策。
1)貼り付けたテキストはA列に入っているのでA1にラベル「org」を入力(適当)。
セルB2に「先頭2文字が全角であれば0を返す」ことを狙い
=if(left($A2,2)=leftb($A2,4)=0,1) と入力した。
単語の最大長がわからないので、とりあえずF列までコピーし、先頭6文字まで対応。
2)B列が0、C列が1であれば「3文字目は半角である」ことが分かるので
該当行のG列に全角の文字数(であると推定される)「2」を入力。
同様に全角文字の数(推定)をG列に書き込んでいくと700件ほど埋まった。
原始的にオートフィルタで絞り込んで入力したのでここは関数なし。
3)G列でフィルタをかけ、本当にセルGnが2のときセルAnが全角2文字+半角なのか目視で確認。
やはり(?)途中に記号や英字が入っていてずれている行がいくつかあった。
ずれのある行のみG列の値を削除。
同様に推定5文字までを検証。
4)H列を「chn」、I列を「eng」と名づけ(これまた適当)
セルH2には中国語(全角)の文字列を取り出すため
=left(a2,g2)
セルG2には残りの文字列(英語)を取り出すため
=right(a2,len(a2)-g2)
これで中国語5文字までの中英対照表が一応できる。
実際は同様に15文字まで作業し、残りは手作業で仕分けした。
それでも1000件ちまちま手作業よりは速いだろうと思う。
透かしの入ったページをきれいにOCRする方法
面白いことを発見した。
支給原稿が紙(又は画像PDF)のとき、たまに透かしや背景画像にぶつかるが
背景画像がOCRに拾われてしまうと該当箇所の文字が読み取れない。
そういうページに限って文字数が多かったりすると捨てるのも忍びない。
読み取りを諦める前に。
ひと手間でかなり救われる場合があるのでメモ。
該当ページの画像ペイントで開き、背景を薄い灰色で塗る。以上。
これだけでモノクロ画像がかなりぼやけるので、
OCRが透かしをただのノイズとして読み捨ててくれるようになる。
今のところ成功率90%。
ほぼ完全に読み取りたい文字が目視できている(テキストにもできている)。
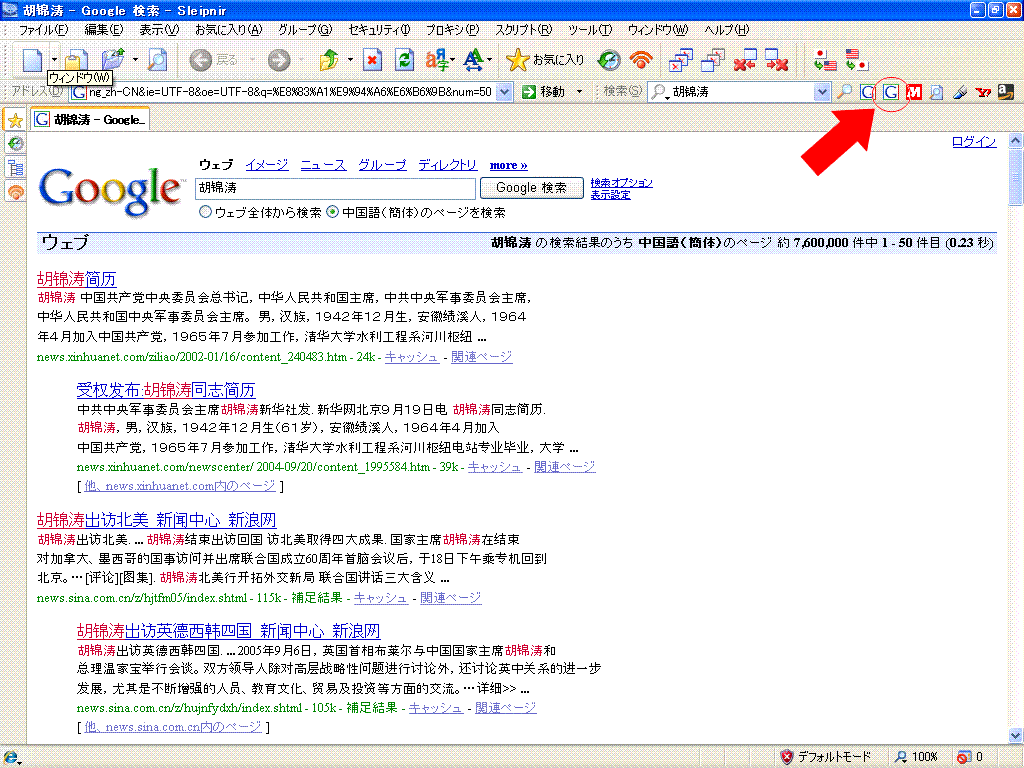
sleipnirの検索バーで簡体字のGoogle検索
タブブラウザsleipnirは強力なカスタマイズが特長。
最新版には簡体字メニューもあるものの、検索バーへの入力は日本語が想定されている模様。
そのまま簡体字の語句を入れて検索すると、日本語にない文字は「?」で置き換えられてしまうため、検索精度がいまいち。
そこで早速カスタマイズ。簡体字でGoogle検索できるように設定を自分で変更!
手順(というほどでもないか)
-「ツール」-「sleipnirオプション」-「検索」-「検索エンジンリスト」を開く
-「Google(日本語)」を選択 – 「新規」ボタンクリック。
-図のように各設定を入力。

-「リクエスト」欄は「http://www.google.com/search?lr=lang_zh-CN&ie=UTF-8&oe=UTF-8&q={all}&num=50」
-次に左のリストから「カスタム検索ボタン」を開く
-下の検索エンジンリストにGoogle(簡体字)が出るので、これを「追加↑」
-「OK」ボタンで閉じる
→検索バーの右に新たなGoogleボタン(=簡体字検索用)が。